How High Volume MGAs Automate Insurance Submission Triage Across EZLynx, Portals, and Email
Leanware·
A specialty wholesale broker handling 800 submissions a month does not have an underwriting problem. It has an intake problem. Submissions arrive through five carrier portals, through EZLynx, and through a shared email inbox, each in a different format, and a person has to read every one, figure out what it is, check it for completeness, and decide which underwriter and carrier it should go to.
That manual step, insurance submission triage, is where volume starts consuming staff capacity, and it is the step most MGAs are still doing by hand.
This is a lifecycle walkthrough built around Meridian Specialty Underwriters, a fictional but representative MGA modeled on a real submission-processing pattern: 800 monthly submissions across EZLynx, five carrier portals, and email. It is written for two readers.
The operations executive who watches manual routing eat the team's capacity, and the principal who knows that inconsistent routing decisions create audit and governance exposure that does not show up until a carrier asks for the records.
Let's see how high-volume MGAs solve this problem.
Why Submission Triage Breaks Down at Multi-System MGAs
The root cause is architecture, not operator skill. EZLynx, the carrier portals, and the shared email inbox were each built to do their own job well. None of them was designed to feed a unified intake layer, and there is no native connection that joins them into a single queue a triage process can work from. The result is three friction points that compound at volume.
Duplicate submission detection fails because the same account can arrive through two channels, a broker emails the ACORD form and also enters it in a portal, and nothing reconciles the two into one record. Metadata extraction is inconsistent because a structured EZLynx field and a scanned PDF in the email inbox carry the same information in completely different forms.
And there is no single routing decision record, so when a submission is misrouted or delayed, no one can reconstruct what data drove the decision or who made it. At Meridian's volume, these are not occasional annoyances. They are the daily texture of the intake operation.
The Three-Channel Intake Problem: EZLynx, Portals, and Email
Each channel produces its own data schema, and that is the problem before routing logic ever runs.
EZLynx delivers structured fields. The data is clean, labeled, and machine-readable, which makes it the easiest channel to work with and the one that sets the false expectation that the others will be similar.
Carrier portals deliver PDFs. A submission downloaded from a portal is a document, not a data object, and the fields a routing rule needs are locked inside a layout that varies by carrier.
Email delivers free-form text with ACORD attachments. The body of the message may carry context that never made it onto the form, the attachment may be a clean ACORD or a scanned image of one, and supplemental documents arrive in whatever format the broker had on hand.
Before any routing rule can fire, all three have to be normalized into a single consistent schema. That normalization gap, converting a portal PDF, an email attachment, and an EZLynx record into the same structured shape, is the engineering problem most MGA ops teams underestimate, because it does not look like work until you try to automate around it.
Meridian's intake log made it visible: the same coverage type appeared as a tidy field from EZLynx and as a phrase buried in a PDF from a portal, and nothing connected the two.
The Hidden Compliance Risk of Manual Routing Decisions
The compliance argument is specific. When a routing decision is undocumented or applied inconsistently from one submission to the next, that gap is commonly treated as an evidentiary weakness in a carrier audit, and it can create errors-and-omissions exposure when a submission is misrouted or delayed past a binding deadline.
Two failure modes matter most to a principal. A missed placement, where a submission that should have gone to a particular carrier was routed elsewhere or stalled, can create E&O exposure if the broker had a duty to place it and the record cannot show why it did not happen.
And inconsistent records, where similar submissions were routed differently with no documented reason, may fail the principal oversight requirements that govern how an MGA supervises its own underwriting authority. A principal reading this should recognize the shape of their own audit risk: not a single catastrophic error, but a pattern of decisions no one can reconstruct.
This framing describes operational risk and should not be read as legal advice. The specific E&O and regulatory implications depend on jurisdiction and carrier agreements, and this section warrants review by qualified counsel before it is relied on.
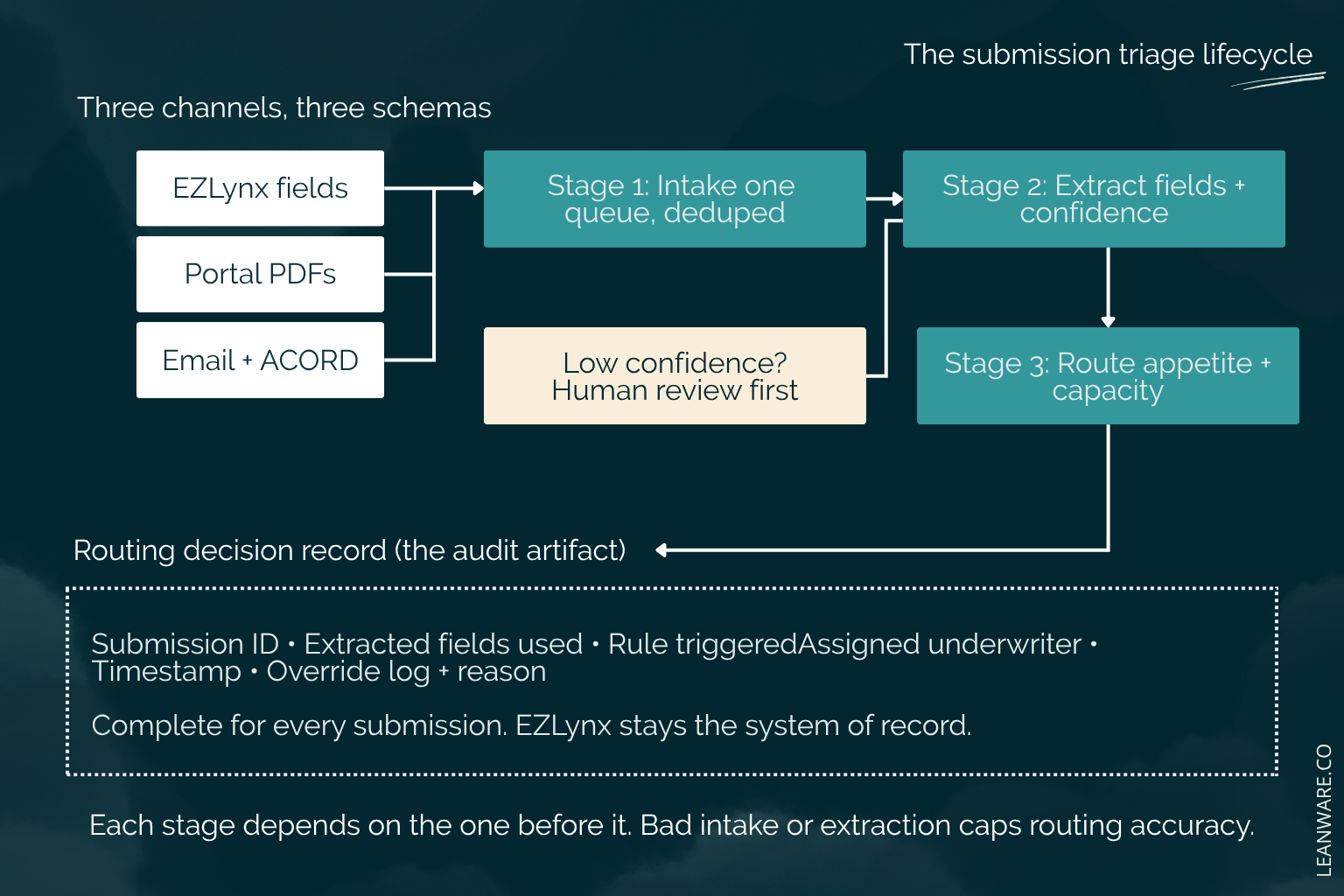
The Submission Lifecycle: Intake, Extraction, and Routing Defined
Triage automation has three stages, and naming them precisely matters because the rest of the architecture maps to them. Intake is the multi-channel ingestion and deduplication problem: capturing every submission from every channel into one queue without duplicates or gaps.
Extraction is converting unstructured documents into the structured fields that routing rules can evaluate. Routing is the rules-based decisioning that matches those fields against underwriter capacity and carrier appetite and produces a documented assignment. Each stage depends on the one before it, and a weakness in an early stage caps the quality of everything downstream.
Stage One: Capturing Every Submission Regardless of Channel
A properly designed intake layer unifies three input types into a single submission queue: EZLynx API events, carrier portal triggers (webhooks where the portal supports them, monitored retrieval where it does not), and parsed email with its attachments.
Conceptually, each channel feeds an ingestion process that writes a normalized submission record into one queue, with deduplication running at the point of entry so that the same account arriving twice becomes one record with two noted sources.
When Meridian implemented a unified intake layer, the immediate operational change was visible before any routing improved. Every submission appeared in one place. Duplicate detection fired on accounts that had previously been worked twice. Nothing fell through the gap between a portal and the inbox, because there was no longer a gap, only a single queue.
Stage Two: Turning Unstructured Data into Underwriting-Ready Records
Extraction is where the difficulty concentrates. ACORD forms, loss runs, and supplemental attachments have to produce structured fields, SIC code, coverage type, limit size, loss history, before a routing rule can read them.
LLM-based document parsing handles this better than older template-matching approaches because it reads documents that do not conform to a fixed layout, though it is not a solved problem and its output quality varies with document quality.
This is why confidence scoring matters. Each extracted field carries a confidence level, and extractions that fall below a defined threshold route to a human reviewer before any routing decision is made. A routing system acting on a bad extraction produces more misrouting than the manual process it replaced, because it applies a wrong field consistently and at speed.
The human-in-the-loop escalation path is what keeps low-confidence extractions from becoming confident mistakes. At Meridian, a submission with an ambiguous coverage type or an unreadable loss run went to a reviewer rather than into the routing engine.
Stage Three: Assigning Submissions to the Right Underwriter and Carrier
Routing is a rules engine evaluating extracted fields against two reference sets: underwriter capacity and carrier appetite. The appetite matrix encodes what each carrier will and will not write, by class, size, geography, and loss history, and the engine matches each submission's extracted fields against it to produce an assignment.
The output that matters most is the routing decision record. A complete record contains the submission ID, the extracted fields used in the decision, the specific rule that triggered, the assigned underwriter, the timestamp, and a log of any override and its reason.
This is the audit artifact the compliance principal has never had from a manual process, because a person making the decision in their head leaves no trace of which fields they weighed or which rule they applied. Meridian tracked the reduction in misrouted submissions after implementation against a baseline measured before go-live, which gave the operations executive a number and gave the principal a documented decision trail.
Integrating Triage Automation Into an Existing EZLynx Stack
Most MGAs cannot replace EZLynx, and they should not try. EZLynx is the system of record, and the realistic question is what automating around it means in architectural terms. A triage layer reads from and writes back to EZLynx through API and webhook patterns, leaving EZLynx in place as the source of truth while the automation handles the intake, extraction, and routing that EZLynx was never built to do. The automation wraps EZLynx. It does not compete with it.
What EZLynx Handles Natively vs. Where the Gaps Are
EZLynx manages the policy lifecycle well: it stores accounts, tracks policies, manages renewals, and serves as the agency management backbone. The gaps line up exactly with the three lifecycle stages.
Lifecycle stage
EZLynx native
Requires added automation
Intake
Captures submissions entered directly into EZLynx
Normalizing portal PDFs and email attachments into the same queue
Extraction
Stores structured fields once they exist
Converting unstructured ACORD forms and loss runs into those fields
Routing
Holds assignment data
Evaluating appetite and capacity, producing a documented decision record
This is a scoping map, not a criticism of the product. EZLynx does what an agency management system is supposed to do. Multi-channel intake normalization and AI-driven extraction of unstructured documents fall outside that scope, which is why the automation is additive rather than a replacement.
Building the Middleware Layer: Architecture Patterns for MGA Ops Teams
The middleware bridging EZLynx with external channels rests on three patterns. Event-driven ingestion, using webhooks where a channel supports them and polling where it does not, brings submissions in as they arrive. A data transformation pipeline normalizes every submission into one consistent schema regardless of source. And a write-back mechanism keeps EZLynx current as the system of record, so the automation never becomes a parallel source of truth.
Meridian evaluated three build paths against three criteria: maintenance burden, EZLynx write-back fidelity, and extraction quality for their specific document mix. An iPaaS approach offered fast connection but limited control over extraction. A fully custom integration offered control at a higher build cost. An AI-native platform offered strong extraction with variable EZLynx write-back depth.
The right answer depended on their document types and tolerance for ongoing maintenance, which is the same evaluation any MGA has to run against its own stack.
Carrier Portal Connectivity: The Last Mile of Submission Triage
Most carrier portals do not publish APIs. That single fact shapes the hardest part of the build, because appetite checking and status retrieval then depend on RPA or browser automation rather than clean API calls. Browser automation carries a higher maintenance burden than API integration, since a portal UI change can break the automation overnight, and this is the component MGA automation projects most consistently underestimate.
Meridian managed portal connectivity as an ongoing operational responsibility rather than a one-time build. They put monitoring in place that detected when a portal interaction failed, so a UI-driven breakage surfaced as an alert the same day rather than as a silent gap discovered a week later when submissions had already backed up. Treating the portal layer as something that needs watching, not just building, is the difference between an automation that holds and one that quietly fails.
Measuring the Impact: What Good Triage Automation Looks Like in Practice
Four operational metrics tell you whether triage automation is working, and the discipline that makes them meaningful is setting the baseline before go-live rather than comparing against an industry number afterward.
Meridian tracked all four from day one against pre-automation baselines: submission-to-quote cycle time, routing accuracy rate, extraction confidence score distribution, and compliance documentation completeness. For the operations executive, these numbers say whether the system is doing its job. For the principal, the point is that measurement is built into the system rather than reconstructed after a problem.
Cycle Time: From Submission Receipt to Underwriter Assignment
Cycle time for the intake-to-assignment stage is the cleanest efficiency measure, because that is the span where manual triage creates the most delay. The variance drivers at an 800-submission MGA are channel mix (portal PDFs take longer to process than EZLynx records), document complexity (a clean ACORD moves faster than a manuscript submission with supplements), and underwriter capacity (assignment waits when the matched underwriter is at capacity).
These drivers are why one MGA's baseline will differ from another's, and why the baseline has to be measured on the specific operation rather than borrowed.
Meridian established its pre-automation baseline by measuring the actual time from submission receipt to underwriter assignment across a representative sample, then tracked the same measure at 30, 60, and 90 days after go-live. The 90-day figure, not the day-one figure, is the real result, because the system's extraction accuracy improves over the first weeks as it processes the MGA's actual document mix.
Routing Accuracy and the Compliance Documentation Standard
Routing accuracy is a compliance metric as much as an efficiency one. A misrouted submission can constitute an undocumented decision, which may create E&O exposure and may fail the principal oversight standard if the record cannot show why the submission went where it did.
Framed this way, routing accuracy is not only about getting submissions to the right place but about being able to prove, afterward, that the decision was sound.
A complete routing decision record, the submission ID, the extracted fields used, the rule triggered, the assigned underwriter, the timestamp, and any override with its reason, is what connects documentation completeness to E&O defense readiness and carrier audit requirements. When the record is complete for every submission, an audit becomes a retrieval exercise rather than a reconstruction.
This section describes operational risk and audit-readiness, not a legal standard, and the specific compliance implications warrant review by qualified E&O or insurance regulatory counsel before being relied on.
Final Thoughts
MGA triage automation is an integration challenge, not a replacement challenge. EZLynx stays in place as the system of record, and the automation wraps around it to solve the intake, extraction, and routing that EZLynx was never built to handle. Every MGA's stack differs on channel mix, document types, submission volume, and compliance obligations, which is exactly why the architecture has to be decided against the specific stack rather than bought off a shelf.
Leanware builds these integration layers for MGAs running EZLynx: custom-built andmanaged end-to-end, not a self-serve platform you configure and maintain yourself. The right starting point is an AI ROI Assessment that maps your channel mix, document types, and routing logic against your actual stack and tells you what is worth building.Start with the AI ROI Assessment.
Frequently Asked Questions
What happens to in-flight submissions during the transition to automated triage?
Cutover is a managed transition, not a single switch thrown overnight. A properly sequenced rollout runs the automated intake layer in parallel with the existing manual process for a defined window. Meridian ran a two-week parallel period: both channels active, the automated layer producing routing decisions that were compared against the manual decisions but not yet acted on, and every discrepancy logged for calibration. Once the comparison showed the automated routing matching or improving on the manual decisions consistently, the team cut over fully. In-flight submissions during the window were handled by the existing process, so nothing in motion depended on the new system until it had proven itself.
How are routing rules maintained as carrier appetite changes?
Routing rules in a properly built system live as configuration, not code, which means an appetite change is a rules update rather than a software redeployment. When a carrier narrows or expands what it will write, the appetite matrix is updated in the rules layer and the engine reflects it immediately. In Meridian's setup, the Leanware team owns that maintenance rather than the MGA's internal staff, and updates are triggered by three events: a carrier communication announcing an appetite change, a failed-routing flag that surfaces a rule no longer matching reality, and a scheduled quarterly review. The MGA does not have to keep the rules current itself.
Can the extraction layer handle non-standard ACORD supplements and manuscript submissions?
Standard ACORD forms are the baseline, but commercial property MGAs regularly receive non-standard supplements and manuscript endorsements that do not map cleanly to structured fields. LLM-based extraction handles these better than template-matching, which simply fails on anything outside its template, but it produces lower confidence scores on non-standard documents. That is exactly why the confidence-scoring and human-escalation path from Stage Two matters. Meridian set a confidence threshold below which a submission routes to a human reviewer before any routing fires. The reviewer confirms or corrects the extracted fields, and only then does the submission enter the routing engine, so a hard-to-read manuscript submission becomes a reviewed record rather than a confident mistake.
What does the compliance documentation standard look like in a carrier audit?
When an auditor examines submission routing, they typically review the submission receipt timestamp, the extracted fields used in the routing decision, the rule that was triggered, the assigned underwriter, any override and its documented reason, and the final disposition. A routing decision record containing all of these is commonly treated as complete, though what satisfies a specific carrier or jurisdiction varies. Meridian's first post-implementation carrier audit produced a complete routing log straight from the system with no manual reconstruction required, which is an illustrative outcome rather than a guarantee. The specific documentation requirements for your carrier agreements and jurisdiction warrant confirmation by qualified counsel.
How does an MGA know whether its submission volume justifies a custom integration layer over a packaged tool?
Two signals point toward a custom layer rather than a packaged tool. First, a document mix that includes non-standard supplements or manuscript submissions, which packaged tools extract poorly because they are tuned for standard forms. Second, routing logic that depends on matching against a proprietary carrier appetite matrix rather than a generic ruleset. Below roughly 150 submissions a month with standard ACORD-only intake and simple routing, a packaged tool may clear the bar. Above that, with complexity on either the document or the routing dimension, packaged tools tend to fail at extraction quality or routing fidelity. An AI ROI Assessment is the mechanism to determine which side of that line a specific MGA sits on, because it evaluates the actual document mix and routing logic rather than assuming.
We use analytics cookies to see how the site is used and make it better.
Essential cookies stay on either way. Read our
Privacy Policy
.